

MLPerf Inference is probably the extra thrilling of the MLPerf benchmarks. Whereas coaching generally has a big cluster from Google or Microsoft, the inference facet lends itself higher to the proliferation of AI {hardware} that matches in distinctive energy budgets or that’s optimized for particular fashions. With the brand new v4.0 suite, MLPerf added a Steady Diffusion picture era and a Llama 2 70B (checkpoint licensed by Meta for benchmarking) check. Nonetheless, it’s primarily a NVIDIA affair.
NVIDIA MLPerf Inference v4.0 is Out
MLPerf Inference v4.0 now makes use of bigger fashions.

The Llama 2 70B and the Steady Diffusion XL fashions are the large new workloads added to the suite. Each are extremely related right this moment.
MLPerf has choices for each server throughput and latencies. Typically, within the “server” set we see the Hopper and Ada Lovelace NVIDIA information middle elements. Within the edge, we get a number of the Ada Lovelace era. Extra importantly, we additionally get all the corporations doing exams on Raspberry Pi’s, NVIDIA Jetson, CPUs, and extra.

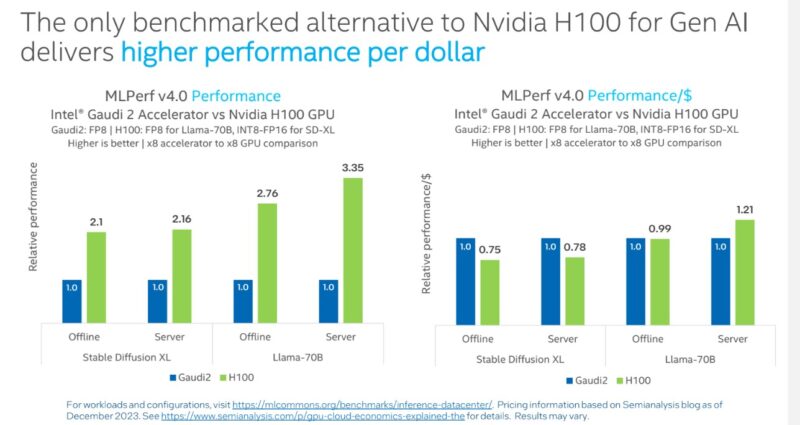
Intel put its Gaudi 2 elements into this iteration. Google had a single TPU v5e consequence. Within the MLPerf outcomes, NVIDIA was a lot sooner on a per-accelerator foundation however was probably higher on a performance-per-dollar foundation. Primarily based on this, a NVIDIA H100 appears to be within the 2.75-2.8x the price of the Gaudi 2. Intel has already mentioned Gaudi 3 so we count on that to make its means into future variations.
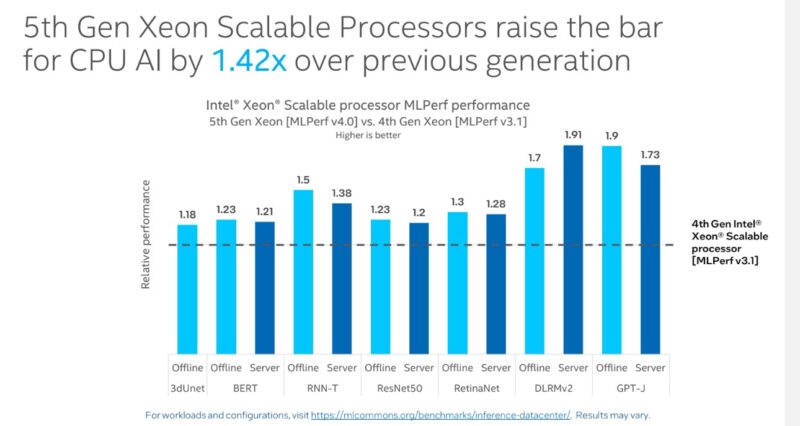
Intel additionally submitted its CPUs. Whereas devoted accelerators are sooner, the CPU AI efficiency will turn out to be an important baseline metric as we advance, as that is the “free” AI efficiency in servers that helps decide if a devoted AI accelerator can be deployed.
Qualcomm Cloud AI playing cards confirmed up once more. MLPerf appears to be Qualcomm’s major advertising and marketing device. It has a brand new take care of Cerebras and its WSE-3 AI Chip, so Cerebras can do the coaching, and Qualcomm can present inferencing {hardware}. OEMs have informed us they’re fascinated with Qualcomm to get leverage over NVIDIA. Realistically, what has occurred, nevertheless, is that for a lot of clients, it’s laborious to get off the NVIDIA bandwagon. Higher stated, OEMs wouldn’t have a lot leverage over NVIDIA, even when they provide Qualcomm Cloud AI elements. As a substitute, clients seeking to deploy servers for inference over a 3-5-year horizon often use NVIDIA as a result of it’s the protected selection.

Qualcomm could be higher off utilizing the Cerebras mannequin of not submitting to MLPerf for advertising and marketing. Presently, it’s attempting to make use of logic towards what has successfully turn out to be NVIDIA’s benchmark undertaking. Clients give attention to the emotional facet of figuring out NVIDIA can be all issues AI. That uneven advertising and marketing method not often works. Allow us to make it simpler. STH is the biggest server, storage, and networking evaluate website round, and our YouTube channel is pretty huge, with 500K YouTube subs. We’ve been reviewing multi-GPU AI servers since ~2017 or so. We’ve by no means had a server vendor inform us there may be such demand for Qualcomm elements that they want opinions of the answer. That’s surprising and telling on the identical time.
On the sting facet, the NVIDIA Jetson Orin 64GB made fairly a couple of appearances. We simply did a NVIDIA Jetson Orin Developer Kits the Arm Future Video. In anticipation of this.
This was additionally the primary time we noticed a Grace Hopper lead to MLPerf Inference. NVIDIA simply launched Blackwell and made it clear that the highest-end AI coaching and inference servers can be Arm + Blackwell in 2025 (Cerebras apart.)
Remaining Phrases
We all know that the AMD MI300X is a multi-billion greenback product line this yr. We all know that Cerebras has a $1B+ income coaching answer. We have no idea the precise dimension of the Intel Gaudi market, however we all know they have been supply-constrained in 2023 and have a brand new Gaudi 3 half for 2024. The MI300X, Gaudi 3, and Cerebras have been no-shows on the most recent MLPerf leads to the server market.
Whereas we did get a single Google TPU v5e consequence and a handful of Qualcomm outcomes, that is nonetheless a NVIDIA-dominated benchmark. NVIDIA dominates the AI dialog, so maybe that is sensible. For many distributors, it appears the technique of simply staying away from MLPerf benchmarking has not inhibited success since it’s so closely NVIDIA.





